
지난해 9월, ‘블레이드앤소울(이하 블소) 토너먼트 2018 월드 챔피언십’에서 엔씨소프트의 ‘블소 비무 AI’가 정상급 프로게이머를 상대로 접전을 펼치며 화제가 된 바 있다.
블소 비무 AI의 성장 비결은 무엇일까? 2019 넥슨 개발자 컨퍼런스(NDC)에서 그 궁금증을 해결할 수 있었다.
엔씨소프트 게임 AI랩 문상빈 연구원은 블소 비무 AI의 발전 이유를 ‘강화학습’에 있다고 설명했다. “손으로 짠 규칙 기반의 AI는 확장 가능성이 낮아 강화학습 기반의 다양한 AI를 구성했다.”고 말했다.
특히, ‘역사’ 직업으로 개발된 블소 비무 AI는 실력은 물론, 보는 재미를 위해 세 가지의 서로 다른 스타일로 구현됐다. AI의 직업을 역사로 선택한 이유에 대해 “블소 토너먼트 대회에 등장하는 꾸준한 직업이자, 근거리 캐릭터이기 때문에 분석이 용이했다.”라고 설명했다.

물론, 과정이 순탄한 것은 아니었다. 블소 비무 AI는 개발 과정에서 총 4가지의 도전 과제를 마주했다. 그중 첫 번째는 블소의 높은 복잡도다. 블소는 스킬의 경우의 수, 이동 방법, 타겟팅, 평균 게임 길이 등을 고려해야 하는 만큼, 복잡도가 상당한 편이다.
두 번째는 게임의 실시간성이다. 실시간으로 진행되는 비무의 특성상 AI가 생각할 수 있는 시간이 부족하다. 또한 0.1초 단위의 즉각적인 행동을 취해야 하기 때문에 알파고처럼 몇 수 앞을 내다보는 탐색 기반의 학습이 적합하지 않다.
세 번째는 일반화다. 각 프로게이머의 플레이 스타일이 다양하고, 누구를 상대하게 될지 알 수 없기 때문에 미지의 상대에 대해 최적의 대응을 할 수 있도록 일반화가 필요하다.
네 번째는 전투 스타일 부여다. 공격형, 밸런스형, 수비형으로 이뤄진 세 가지의 다른 전투 스타일을 구현해야 했기 때문에 학습에 보다 어려움이 있다.
엔씨소프트는 이 같은 문제들에 대응하기 위해 강화학습을 활용했다. 블소 비무 AI에 활용된 강화학습 모델은 ‘액터-크리틱(Actor-Critic) 모델’로 상대의 공격 패턴이 바뀌더라도 행동 확률에 따른 최적의 의사 결정 정책을 학습할 수 있는 것이 특징이다.

블소 비무 AI의 강화학습은 보상의 합을 최대화하는 것을 목표로 한다. 이는 자신의 행동 정책을 수정하면서 이뤄지는 것으로, 좋은 행동은 강화하고 나쁜 행동을 약화하면서 정책을 수정한다.
이 같은 강화학습은 ‘보상’을 통해 이뤄진다. 큰 틀에서 블소 비무 AI의 보상은 승패지만, 승패는 게임이 끝나야만 알 수 있기 때문에 드물게 얻는 보상이다. 때문에 엔씨소프트는 추가적으로 HP 득실을 보상으로 제공했다.
상대 HP가 줄어든다면 좋은 행동이기 때문에 강화하며, AI의 HP가 줄어드는 것은 나쁜 행동이기 때문에 약화하면서 정책을 수정하는 것이다.
전투 스타일은 추가적인 보상 변형(reward shaping)을 통해 구현했다. 예를 들어 공격형 AI에게는 HP 비중과 관련된 보상에 가중치를 주고, 비무를 진행하는 시간이 길어지거나 상대와의 거리가 멀어지면 페널티를 부여하는 방식이다.
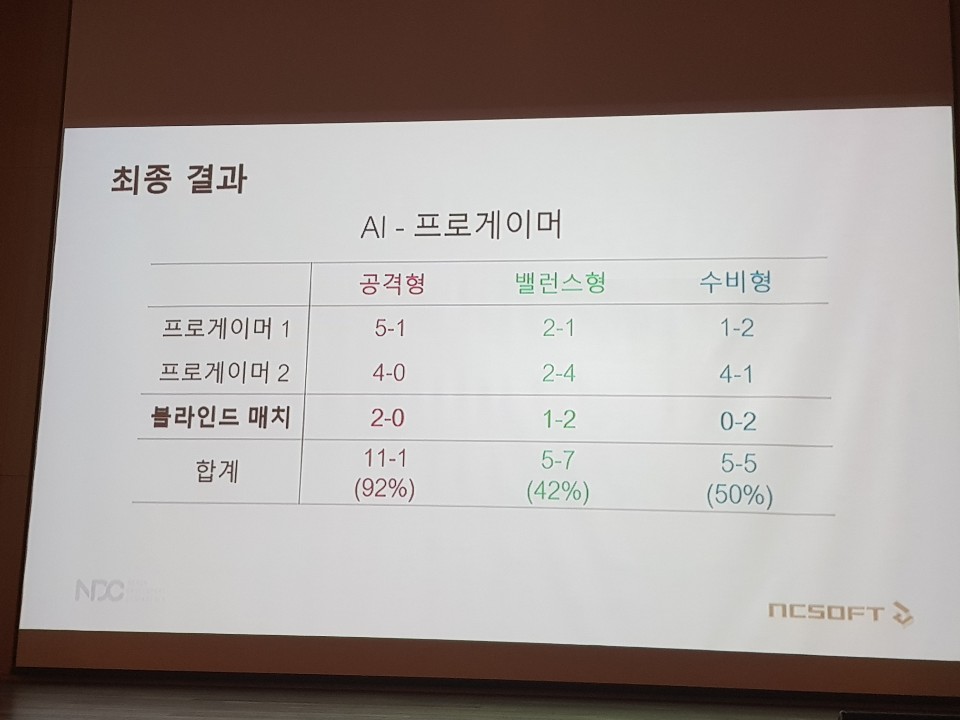
이러한 일련의 과정을 통해 비무 AI는 학습을 하게 되며, 반복되는 학습 끝에 블소 비무 AI는 공격형의 경우 프로게이머를 상대로 92%(11승 2패)의 승률을 기록했다. 이 밖에도 밸런스형 AI는 42%(5승 7패), 수비형 AI는 50%(5승 5패)의 승률을 기록하는 등 프로게이머 수준의 AI가 탄생했다.